Diese hier ist schon wieder eine wunderbare Idee aus Jimmy Nilssons Applying Domain-Driven Design and Patterns (das Buch scheint bis zur letzten Seite super Tipps zu liefern 😉 ) und zwar von Ingemar Lundberg.
Was ist eigentlich die Aufgabe einer Webseite: irgendwelche Controls mit Text zu füllen. Was dieser Text beinhaltet, dass wird von verschiedenen Funktionen entschieden. (Wie er ausgegeben wird, interessiert nicht.) Die Hauptaufgabe also bei der testgetriebenen Entwicklung von Webforms ist, diese Funktionalitäten zu ermitteln und zu implementieren. So bekommt man eine Webanwendung, bei der die Hauptbereiche getestet sind und nur die eigentliche Html-Ausgabe ungetestet bleibt. Außerdem wird auf dieser Art sichergestellt, dass die View sonst nichts tut.
Nehmen wir ein einfaches Beispiel: das Füllen eines Warenkorbs. Es stehen 3 Produkte zur Auswahl und der Käufer darf in seinen Warenkorb maximal 3 stellen. Um etwas Logik dabei zu haben, wird festgelegt, dass von ein Produkt nur maximal 2-mal gewählt werden darf. Wenn diese Bedingung erfüllt ist, soll das Produkt nicht mehr auswählbar sein. Gleiches gilt, wenn im Korb bereits 3 Produkte sind, kein Produkt darf mehr auswählbar sein.
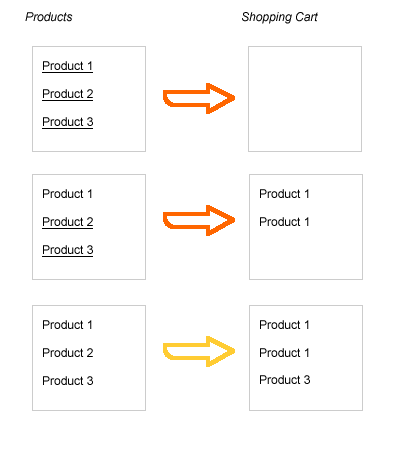
Das Auswählen eines Produktes passiert z.B. mit einem OnClick-Event auf dem Link. Aus der Sicht der Funktionalität ist das nicht wichtig, hauptsache das Event wird ausgelöst.
Was tut also ein Modell um eine View zu steuern: nachdem es sichergestellt hat, dass alle Controls leer sind, lädt es die Daten mit irgendeiner Repository (nennen wir sie IDeposit), gibt sie der View und veranlasst diese, die Daten zu rendern. Danach muss es die übermittelten Daten identifizieren können und, wenn es OK ist, muss es diese mit einer anderen Repository (die nennen wir IAcquisition) abspeichern. Mit diesem “ist OK” wird sichergestellt, dass die obigen Regeln eingehalten wurden, also dass nicht zu viele Produkte bzw. identische Produkte ausgewählt wurden. Danach muss die View die Daten wieder rendern.
Mit diesen Informationen können wir bereits das Produkt und die 2 Interfaces definieren, die wir hier als Blackbox betrachten:
[sourcecode language=”csharp”]
namespace WebformMVP.Tests
{
//Wegen der Bedingung “nicht mehr als zwei vom selben Typ” muss eine Product-Klasse geben. Sonst würde auch ein string reichen
public class Product
{
public string Name;
public int Type;
public Product(string name, int type)
{
Name = name;
Type = type;
}
}
public interface IDeposit
{
IList<Product> Load();
}
public interface IAcquisition
{
void Add(Product product);
}
}
[/sourcecode]
Jetzt ist endlich Zeit für den ersten Test. Wie ich schon am Anfang geschrieben habe, eine View muss einfach nur Text darstellen. Um die View simulieren zu können, wird sie von einem Interface abgeleitet, genauso wie die Testklasse, unsere Fakeview. Diese bekommt als Felder strings anstelle von Controls, die allerdings korrekt gefüllt werden müssen. Wir tun so als ob, wir abstrahieren die View auf das Minimum:
[sourcecode language=”csharp” highlight=”3,4,5,6,9″]
namespace WebformMVP.Tests
{
public interface IShoppingView
{
void AddSourceItem(string text, bool available);
}
[TestFixture]
public class Tests : IShoppingView
{
string m_sourcePanel;
string m_shoppingCartPanel;
[Test]
public void FillSourcePanel()
{
m_model.Fill();
m_model.Render();
Assert.That(m_sourcePanel, Is.EqualTo(“Product 1 available; Product 2 available; Product 3 available; “));
}
}
}
[/sourcecode]
So wird die Anwendung natürlich nicht mal kompiliert :), dazu brauchen wir noch ein paar Schritte.
Dadurch, dass die Testklasse von diesem Interface ableitet, sind wir in der Lage, die Methoden entsprechend überschreiben zu können. Dieser Trick nennt sich Implement Interfaces Explicitly. Gleichzeitig lassen wir die Klasse auch von IDeposit ableiten, um auch dessen Methode zu überschreiben:
[sourcecode language=”csharp” highlight=”4,10,11,12,13,15,16,17,18″]
namespace WebformMVP.Tests
{
[TestFixture]
public class Tests : IShoppingView, IDeposit
{
string m_sourcePanel;
string m_shoppingCart;
IList<Product> m_sources= new List<Product>{new Product(“Product 1”, 1), new Product(“Product 2”, 2), new Product(“Product 3″, 3)};
void IShoppingView.AddSourceItem(string text, bool available)
{
m_sourcePanel += text + (available ? ” available;”: string.Empty) + ” “;
}
IList<Product> IDeposit.Load()
{
return m_sources;
}
[Test]
public void FillSourcePanel()
{
m_model.Fill();
m_model.Render();
Assert.That(m_sourcePanel, Is.EqualTo(“Product 1 available; Product 2 available; Product 3 available; “));
}
}
}
[/sourcecode]
Es funktioniert immer noch nicht, wir brauchen ja noch ein Modell.
[sourcecode language=”csharp”]
namespace WebformMVP.Tests
{
public class ShoppingModel
{
public void Fill()
{
throw new NotImplementedException();
}
public void Render()
{
throw new NotImplementedException();
}
}
[TestFixture]
public class Tests : IShoppingView, IDeposit
{
…
private ShoppingModel m_model;
//Es muss sichergestellt werden, dass beim Laden der View alle Felder leer sind.
[SetUp]
public void Setup()
{
m_sourcePanel = string.Empty;
m_shoppingCart = string.Empty;
m_model= new ShoppingModel();
}
[Test]
public void FillSourcePanel()
{
m_model.Fill();
m_model.Render();
Assert.That(m_sourcePanel, Is.EqualTo(“Product 1 available; Product 2 available; Product 3 available; “));
}
}
}
[/sourcecode]
Ok, es kompiliert endlich! Aber wir gehen ja nach TDD vor, der Test ist wie gewünscht rot :D. Die 2 Methoden Fill und Render sind noch nicht implementiert.
Was sollen die Methoden tun? Fill() sollte eine lokale Liste mit Hilfe der Deposit-Repository füllen und Render() soll diese Elemente in das SourcePanel-Feld der View schreiben. Also muss unser Modell eine Liste, das IDeposit-Interface und das IShoppingVew als neue Member bekommen. Letzteren werden natürlich injectet (s. Dependency Inversion):
[sourcecode language=”csharp” highlight=”3,4,5,18,22,23,24,25,38,39″]
public class ShoppingModel
{
IDeposit m_deposit;
IList<Product> m_products;
[NonSerialized]IShoppingView m_view;
public ShoppingModel(IDeposit deposit)
{
m_deposit = deposit;
}
public void SetView( IShoppingView view )
{
m_view = view;
}
public void Fill()
{
m_products = m_deposit.Load();
}
public void Render()
{
foreach( Product product in m_products )
{
m_view.AddSourceItem( product.Name, true );
}
}
}
[TestFixture]
public class ShoppingCartTests:IShoppingView,IDeposit
{
…
private ShoppingModel m_model;
[SetUp]
public void Setup()
{
m_model = new ShoppingModel(this);
m_model.SetView( this );
m_sourcePanel = string.Empty;
m_cartPanel = string.Empty;
}
[Test]
public void FillSourcePanel()
{
m_model.Fill();
m_model.Render();
Assert.That( m_sourcePanel, Is.EqualTo( “Product 1 available; Product 2 available; Product 3 available; ” ) );
}
…
}
[/sourcecode]
Der Test ist grün! Jetzt ist sicher klar wie es weitergeht und ich will den Artikel nicht noch länger machen. Hier sind also die nächsten Tests und die Implementierung dazu:
[sourcecode language=”csharp” highlight=”12,87,115″]
[TestFixture]
public class ShoppingCartTests:IShoppingView,IDeposit
{
private string m_sourcePanel;
private string m_cartPanel;
private IList<Product> m_products = new List<Product> { new Product( “Product 1”, 1 ), new Product( “Product 2”, 2 ), new Product( “Product 3”, 3 ) };
private ShoppingModel m_model;
[SetUp]
public void Setup()
{
m_model = new ShoppingModel(this, new Cart());
m_model.SetView( this );
m_sourcePanel = string.Empty;
m_cartPanel = string.Empty;
}
…
[Test]
public void AddAnItem()
{
m_model.Fill();
m_model.AddAt( 0 );
m_model.Render();
Assert.That( m_sourcePanel, Is.EqualTo( “Product 1 available; Product 2 available; Product 3 available; ” ) );
Assert.That( m_cartPanel, Is.EqualTo( “Product 1 ” ) );
}
[Test]
public void AddTwoItemsOfAKind()
{
m_model.Fill();
m_model.AddAt( 0 );
m_model.AddAt( 0 );
m_model.Render();
Assert.That( m_sourcePanel, Is.EqualTo( “Product 1 Product 2 available; Product 3 available; ” ) );
Assert.That( m_cartPanel, Is.EqualTo( “Product 1 Product 1 ” ) );
}
[Test]
public void AddThreeDifferentItems()
{
m_model.Fill();
m_model.AddAt( 0 );
m_model.AddAt( 2 );
m_model.AddAt( 1 );
m_model.Render();
Assert.That( m_sourcePanel, Is.EqualTo( “Product 1 Product 2 Product 3 ” ) );
Assert.That( m_cartPanel, Is.EqualTo( “Product 1 Product 3 Product 2 ” ) );
}
…
void IShoppingView.AddCartItem( string text )
{
m_cartPanel += text + ” “;
}
}
public class ShoppingModel
{
IDeposit m_deposit;
IList<Product> m_products;
ICart m_cart;
[NonSerialized] IShoppingView m_view;
public ShoppingModel(IDeposit deposit, ICart cart)
{
m_deposit = deposit;
m_cart = cart;
m_view = view;
m_products = new List<Product>();
}
public void SetView( IShoppingView view )
{
m_view = view;
}
public void Fill()
{
m_products = m_deposit.Load();
}
public void Render()
{
foreach( Product product in m_products )
{
m_view.AddSourceItem( product.Name, m_cart.IsOkToAdd(product) );
}
foreach( Product product in m_cart.List )
{
m_view.AddCartItem( product.Name );
}
}
public void AddAt( int index )
{
var product = m_products[index];
m_cart.Add( product );
}
}
public interface ICart
{
bool IsOkToAdd( Product product );
void Add( Product product );
IList<Product> List { get; }
}
public class Cart :ICart{
private IList<Product> m_cartItems = new List<Product>();
public bool IsOkToAdd( Product product )
{
return m_cartItems.Where( a => a.Type == product.Type ).Count() < 2 && m_cartItems.Count < 3;
}
public void Add( Product product )
{
m_cartItems.Add( product );
}
public IList<Product> List
{
get { return m_cartItems; }
}
}
[/sourcecode]
Die einzige größere Änderung zum ersten Test ist das neue ICart-Objekt. Da es hier um mehr als es eine Liste geht (irgendwo muss ja die Logik der maximal 2 gleichen Produkte pro Warenkorb errechnet werden), habe ich dafür das Interface und die Klasse definiert.
Jetzt sind wir fast fertig. Es muss lediglich die abstrahierte Umgebung in eine Webanwendung nachgebaut werden. Das heißt, wir implementieren die Methoden Page_Load(), Pre_Render() und AddAt_Click() und die Methoden des Interface IShoppingView. Um die Kontrolle zu behalten, löschen wir den Designer und schalten den ViewState aus (deswegen mag ich diesen Ingemar so sehr 😉 ).
[sourcecode language=”csharp”]
//default.aspx
<%@ Page Language=”C#” AutoEventWireup=”true” EnableViewState=”false” CodeBehind=”Default.aspx.cs” Inherits=”ShoppingCart.Web._Default” %>
<html xmlns=”http://www.w3.org/1999/xhtml” >
<head runat=”server”>
<title>Shopping Cart</title>
</head>
<body>
<form id=”form1″ runat=”server”>
<div>
<asp:Panel runat=”server” ID=”srcPanel”></asp:Panel>
<asp:Panel runat=”server” ID=”cartPanel”></asp:Panel>
</div>
</form>
</body>
</html>
//default.aspx.cs
using System;
using System.Collections.Generic;
using System.Web.UI.HtmlControls;
using System.Web.UI.WebControls;
namespace ShoppingCart.Web
{
public class _Default : System.Web.UI.Page, IShoppingView
{
protected ShoppingModel model;
protected HtmlTable srcTable, cartTable;
protected Panel srcPanel, cartPanel;
protected void Page_Load( object sender, EventArgs e )
{
if( !IsPostBack )
{
model = new ShoppingModel(new FakeDeposit(),new Cart());
//Speichern, hier in Session aber sonst natürlich mit einer Repository
Session[“ShoppingModel”] = model;
model.Fill();
}
else
{
model = (ShoppingModel)Session[“ShoppingModel”];
}
model.SetView( this );
ModelRender();
}
protected void Page_PreRender()
{
srcPanel.Controls.Clear();
cartPanel.Controls.Clear();
ModelRender();
}
private void ModelRender()
{
srcTable = new HtmlTable();
srcPanel.Controls.Add( srcTable );
srcTable.Width = “50%”;
srcTable.Border = 1;
cartTable = new HtmlTable();
cartPanel.Controls.Add( cartTable );
cartTable.Width = “50%”;
cartTable.Border = 1;
cartTable.BgColor = “#cccccc”;
model.Render();
}
public void AddSourceItem( string text, bool available )
{
int index = srcTable.Rows.Count;
HtmlTableRow tr = new HtmlTableRow();
HtmlTableCell tc = new HtmlTableCell { InnerText = text };
if( available )
{
LinkButton lb = new LinkButton();
tc.Controls.Add( lb );
lb.ID = index.ToString();
lb.Text = “>>”;
lb.Click += AddAt_Click;
}
tr.Cells.Add( tc );
srcTable.Rows.Add( tr );
}
private void AddAt_Click( object sender, EventArgs e )
{
model.AddAt( Convert.ToInt32( ((LinkButton)sender).ID ) );
}
public void AddCartItem( string text )
{
HtmlTableCell tc = new HtmlTableCell { InnerText = text };
HtmlTableRow tr = new HtmlTableRow();
tr.Cells.Add( tc );
cartTable.Rows.Add( tr );
}
}
internal class FakeDeposit :IDeposit
{
public IList<Product> Load()
{
return new List<Product> { new Product( “Product 1”, 1 ), new Product( “Product 2”, 2 ), new Product( “Product 3”, 3 ) };
}
}
}
[/sourcecode]
Fertig. Ich muss eingestehen, als ich das Beispiel aus dem Buch nachprogrammiert habe, war ich wirklich überrascht, wie alles geklappt hat, obwohl ich während des Testens keine Webseite angesprochen habe. Die Wahrheit ist, ich habe noch nie nach dem MVP-Pattern entwickelt, aber eine Webseite so aufzusetzen ist genial! Hoch lebe die Abstraktion!
Ich lade hier das Projekt hoch, vielleicht glaubt es mir jemand nicht 😉
