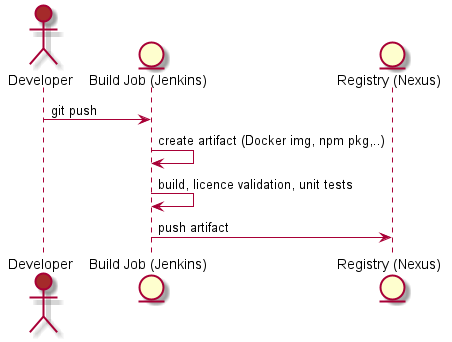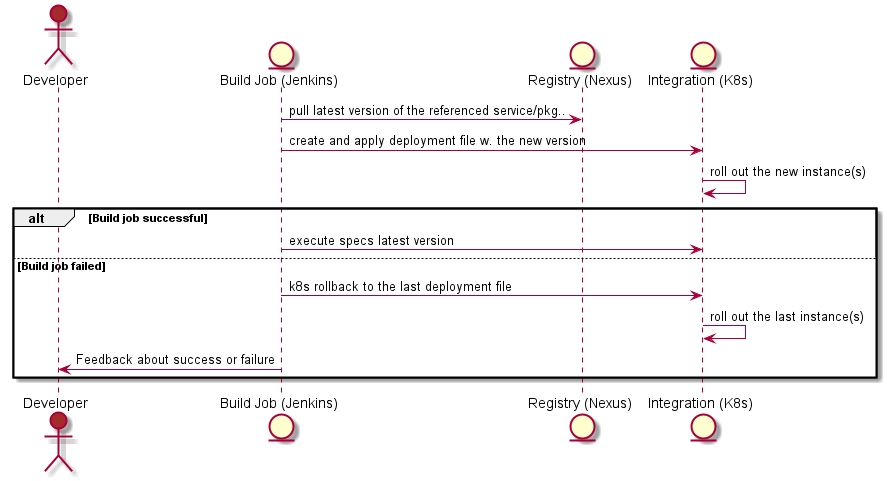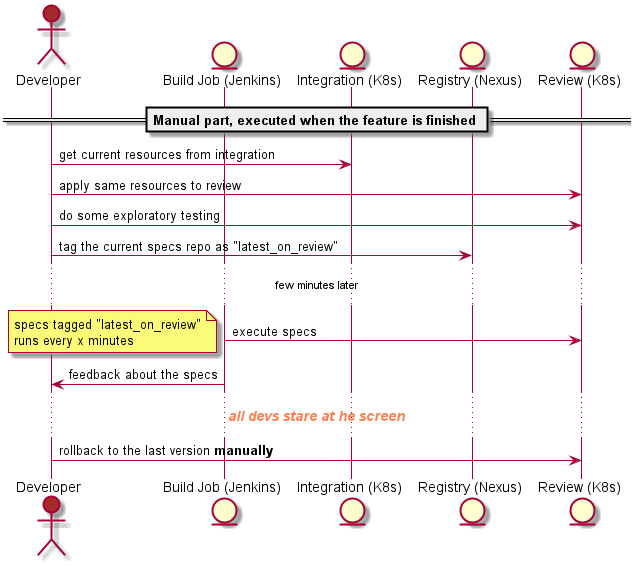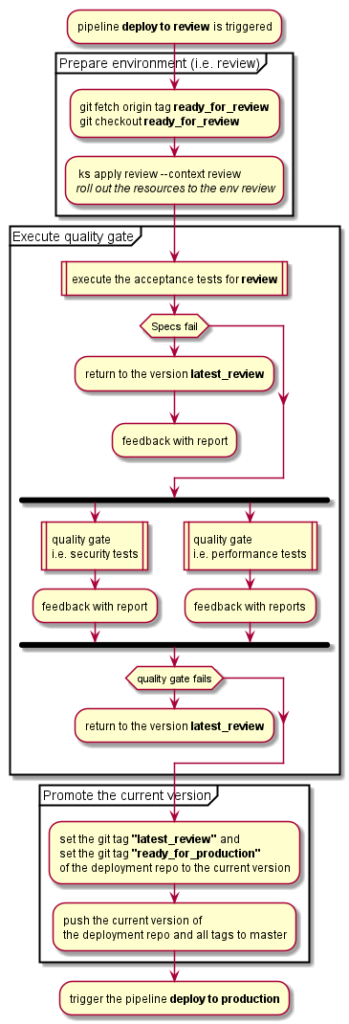
Tl;dr: Continuous integration and delivery are not about a pipeline, it is about trust, psychological safety, a common goal and real teamwork.
What is needed for CI/CD – and how to achieve those?
- No feature branches but trunk-based development and feature toggles: feature branches mean discontinuous development. CI/CD works with only one temporary branch: the local copy on your machine getting integrated at the moment you want to push. “No feature branches” also means pushing your changes at least once a day.
- A feeling of safety to commit and push your code: trust in yourself and trust in your environment to help you if you fall – or steady you to not fall at all.
- Quality gates to keep the customer safe
- Observing and reducing the outcome of your work (as a team, of course)
- For example by using the metric Mean Time to Recover
- Resilience: accept that errors will happen and make sure that they are not fatal, that you can live with them. This means also being aware of the risk involved in your changes
What happens in the team, in the team-work:
- It enables a growing maturity, autonomy due to fast feedback, failing fast and early
- It makes us real team-workers, “we fail together, we succeed together”
- It leads to better programmers due to the need for XP practices and the need to know how to deliver backwards compatible software
- It has an impact on the architecture and the design (see Accelerate)
- Psychological safety: eliminates the fear of coding, of making decisions, of having code reviews
- It gives a common goal, valuable for everybody: customers, devs, testers, PO, company
- It makes everybody involved happy because of much faster feedback from customers instead of the feedback of the PO => it allows to validate the assumption that the new feature is valuable
- It drives new ideas, new capabilities bc it allows experiments
- Sets the right priorities: not to jump to code but to think about how to deliver new capabilities, to solve problems (sometimes even by deleting code)
How to start:
- Agree upon setting CI/CD as a goal for the whole team: focus on how to get there not on the reasons why it cannot work out
- Consider all requirements (safety net, coding and review practices, creating the pipeline and the quality gates) as necessary steps and work on them, one after another
- Agree upon team rules making CI/CD as a team responsibility (monitoring errors, fixing them, flickering tests, processes to improve leaks in the safety net, blameless post-mortems)
- Learn to give and get feedback on a professional manner (“I am not my work”). For example by reading the book Agile Conversations and/or practice it in the meetup
– – – – –
This bullet-point list was born during this year’s CITCON, a great un-conference on continuous improvement. I am aware that they can trigger questions and needs for explanations – and I would be happy to answer them 🙂