My second day at the Spartakiade was dedicated to the subject of graph databases.
In computing, a graph database is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A graph database is any storage system that provides index-free adjacency. This means that every element contains a direct pointer to its adjacent elements and no index lookups are necessary. General graph databases that can store any graph are distinct from specialized graph databases such as triplestores and network databases. (source: Wikipedia)
The workshop was led by Stephan (@Piratevsninja) – thank you very much! – and we used Neo4j, the most popular open source graph database. After this day of dive-in I can say I can start to create my first graph database application without asking myself all the time what the hell am I doing 🙂
Also: what is a graph database?
On a very high level we can split the databases into two types: RDBMS and NoSQL. In other words: into relational and nonrelational storages.
NoSQL databases – called by Martin Fowler Not Only SQL have the main focus on the data model and not on the relations between the data. Mostly there isn’t any relation between the entities. They can be differentiated based on the data model they use. Here some examples: Key-value storages (Redis, CouchDB, etc.), Document DBs (Lotus Notes, MongoDB, etc.), Column based DBs (Cassandra, HBase, etc.).
Relational databases (RDBMS) store the data denormalized and define the relations between the data types (also ALL the entries of one type). I don’t think I have to give examples for our plain old databases: if you can join and distinct data you are in the world of relational databases.
Graph databases combine both worlds: they are relational databases with the main focus on the relations between the data (not between the data model) – or like Stephan formulated it: they put data in the context of relationships.
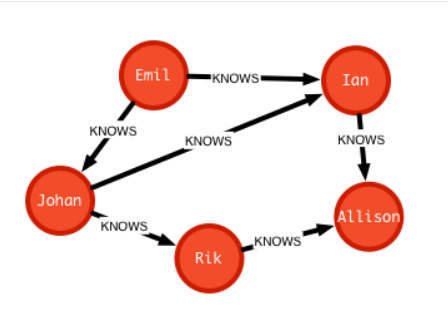
How you define the content ?
A graph database contains nodes (instances like “Emil” and “Ian”) and relations between these nodes (“knows”). One node is defined through some properties and can be grouped through labels. They often have aliases to be easier to work with them:
Emil:Person {name:"Emil", age:"20"}, Ian:Person {name:"Ian"}
One relation is defined through a name, the nodes it connects and the direction of this connection. Relations can also have properties but they should be very carefully chosen. They must describe the relation and not the nodes.
(Emil)-[:KNOWS {certainty:100}]->(Ian)
Now is clear to see what is the difference between a “plain” relational and a graph database: for the former you care always about the data. For the latter the data means nothing without the relation to some other data.

Fine, I can set actors in relations. So what?
The most important point is: think around a corner. The fact that I can report that Ian knows Emil and Johann knows Emil too can be interesting but I don’t think there are any new business ideas in the domain of social connections which weren’t evaluated yet. What about the information that only 20% of the Swedish tourists who visit Germany and are between 18 and 25 do not speak German? This is surely a VERY interesting to know if you sell German dictionaries in the near of Universities…
I just invented this idea – I have no idea how many Swedish guys between 18 and 25 are speaking German 😉 – but this is what I mean with think around a corner!
What else remains to do?
After giving a good thought to the design: the relations and the connected data – like ids and oder characteristics but only if they are must-have – there are only a few things to do. Neo4j just like all the other graph databases have some kind of API to create, insert, update and query data. You only have to save the data across your application and create a UI (or use the one from Neo4j which is one of the coolest UI I ever saw) to create reports. Put this reports in front of the business analyst and you are done!
 Alle Verwender von DotNetOpenAuth.OpenId
Alle Verwender von DotNetOpenAuth.OpenId Interne Abhängigkeiten von DotNetOpenAuth.OpenId
Interne Abhängigkeiten von DotNetOpenAuth.OpenId