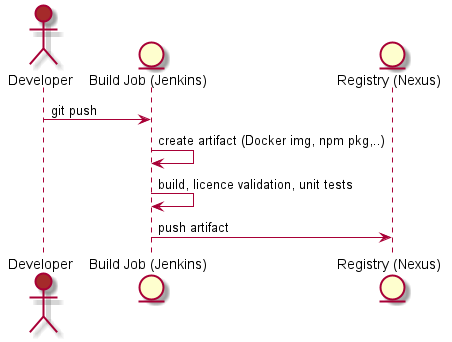
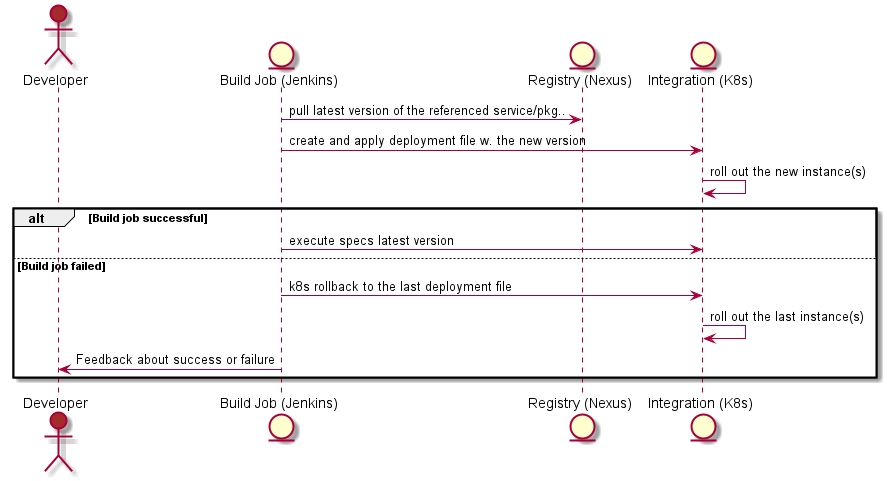
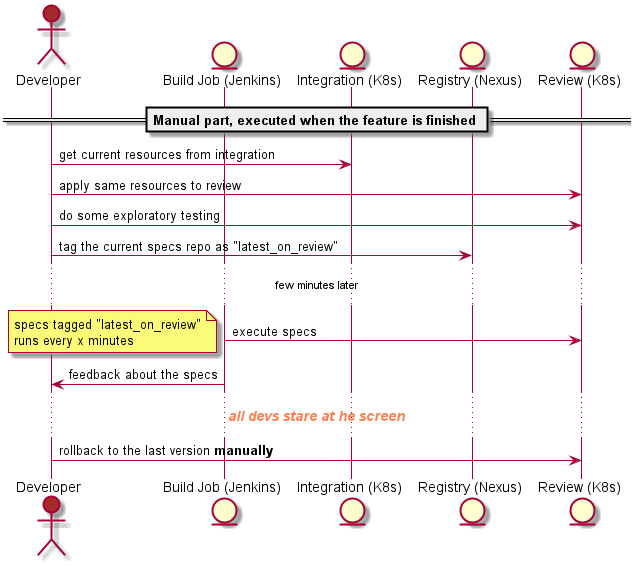
… but if you do then you should stop reading here. It is Ok for me.
How many of you have built features in backend services which were never used in any application? Or implemented requests in the wrong way because nobody cared to give you the whole story, the whole problem this feature should solve? Or felt demotivated because of the lack of feedback, if that what you do makes an impact, or it was wasted energy and time? How many of you are still working under these unsatisfying circumstances? For those of you is this article.
I did all of this. One case I will never forget: I should implement a feature request resulting in returning some object property as a string. This property was containing a URL, but the feature didn’t say “I need to know how to navigate to X or Y” but “please include the URL X in the result”.
It turned out that another 2 teams used this “string” to build navigation on it or to include it in emails without ever telling me. Why should they? I was done with the feature: it was their turn. Both of them have validated this string, have built URLs with them (using information exclusively owned by the backend service…), etc.
Let me be more explicit:
Failure No. 1: If I would have changed some internals in the backend service, I could’ve broken the UI code without knowing. My colleagues relied on things they had no chance to control. We were dependent on each other without being able to see it.
Failure No. 2: the company paid 3 different developers to write the same validation functions and the customer flow had to pass the same validations 3 times instead of only once. A totally wrong decision, from an economical point of view.
I think that was the moment I decided to change the way we deliver features, the way we work together. This was 6 or 7 years ago and since then I followed the same method to reorganize not only the teams but also the source code. Because one thing is sure: changing one without the other only leads to bigger pains and even more frustration.
Step 1. Visit the “other side” of that wall and learn what they are doing and how they are doing it. You will observe bottlenecks and wasted time and energy in your value stream (the road a feature passes from the idea to the customer)
Step 2. Get the buy-in by the next level in your hierarchy: in most situations (in both cases I were in this situation) you are not the first one noticing these problems, but you could be the first one offering a solution. Grab this chance, don’t hesitate!
Step 3. Remove the wall between the silos: find a good time to make your move, after the biggest project ended or before the next one starts. Don’t wait too long, there always will be unfinished features.
Step 4. This depends on how many team members we are talking about. In both cases, we were around 15 people, and nobody wants stand-ups or even meetings with 15 people! You become even slower and even less capable to take decisions. But this step is important for a few things:
- both “parties” should learn and understand what the others do, how the parts are connected, what language, concept, design is used to build them
- all members should understand and accept that it is important to split up in teams – and this is always hard because it means “we have to change”! Developers are – against all expectations – very reluctant to change. Even more reluctant when they realize that they won’t work with their buddies anymore but with some hardly known people they do not really or trust.
- you and/or your boss, your colleagues, your buddy in this change must start to discover how the domain is shaped, how can the teams being split up – because this will be the next step.
Up to this point you didn’t improve the developer experience, it will become rather worse. What you have improved is the life of the product manager or CTO or whoever brings the requests to the teams: instead of explaining two teams the two parts of a feature (cut in the “middle” between backend and frontend), he/she must explain it only once. At the same time, the Delivery Lead Time (the first key metric in measuring team performance) will become shorter because all the ping-pong between BE and FE can be eliminated before the feature development starts.
After you all spent a longer or shorter time together is time to take the next step: align the organization to the business

The most important part is to find the natural boundaries of the domain and create business teams who OWN this (sub) domains.
I did this 3 times in all kinds of environments: brownfield monolith or greenfield new biz, it doesn’t matter. Having a monolith as cash cow doesn’t make this change easy of course but it can be made, with discipline and a good plan on how to take over control. (this topic is much to complex to be included in this article)
The last thing which must be said is, when NOT to start this transformation:
- If you don’t find any fellow to support you. In this case, either the problem isn’t big enough to be felt by the others, or you are in the wrong company and maybe should start to think to transform yourself instead (and leave).
- If you or your fellow and/or boss aren’t patient people. Changing is hard and should be accompanied carefully and patiently – so that one does not need to repeat it again after even greater frustrations and chaos (was there, saw this :-/ )
- If you expect that this is all. Because it isn’t: every change toward more transparency – because this is what happens when you break up silos and let others look at the existing solutions – all these changes will make issues transparent. A few of these issues will be technical (like CI/CD, code coupling, infrastructure coupling, etc.). But the hard problems will be missing communication skills and missing trust. Nothing that cannot be solved – but it will take time, that is sure.
If you reach this point, you can start to form an autonomous team: one which not only decides, what to do but also in charge to do it. Working in an environment created by you and your team allows you all to discover and live up to your creativity, to make mistakes and learn from them.
This ownership and responsibility make the difference between somebody hired to type lines of code and somebody solving problems.
What do you think? Could you start this change in your company? What would you need?
Now you know about my experience. I would be really happy to find out yours – here or on twitter.
One last question: what would you like more to read of: how to find the right boundaries or how can your team become a REALLY autonomous team – and how autonomous can that be?