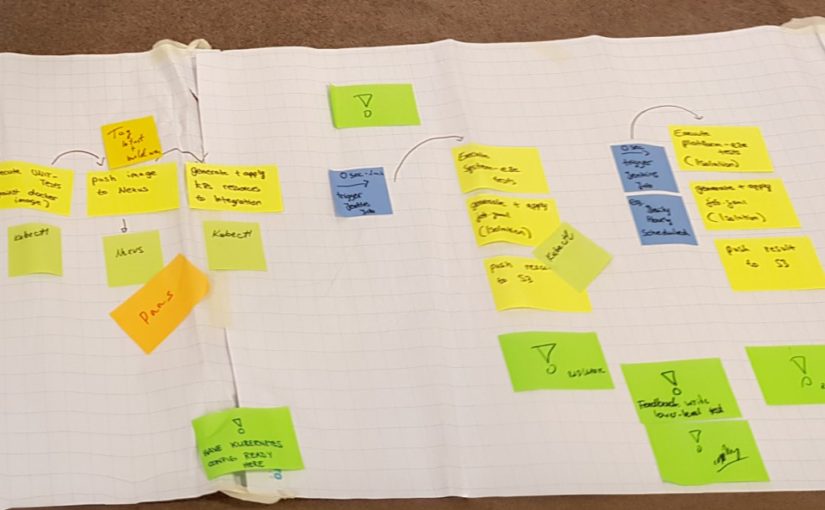
After describing the context a little bit in part one it is time to look at the single steps the source code must pass in order to be delivered to the customers. (I’m sorry, but it is a quite long part 🙄)
The very first step starts with pushing all the current commits to master (if you work with feature branches you will probably encounter a new level of self-made complexity which I don’t intend to discuss about).
I think, if you agree having CD this way (commit ->…->production) than you have implicitly enforced trunk-based development.
This scenario triggered a totally new view on what we could achieve – good and bad 😉 – and made the responsibility on our shoulders palpable.— Krisztina Hirth (@YellowBrickC) March 11, 2019
This action triggers the first checks and quality gates like licence validation and unit tests. If all checks are “green” the new version of the software will be saved to the repository manager and will be tagged as “latest”.
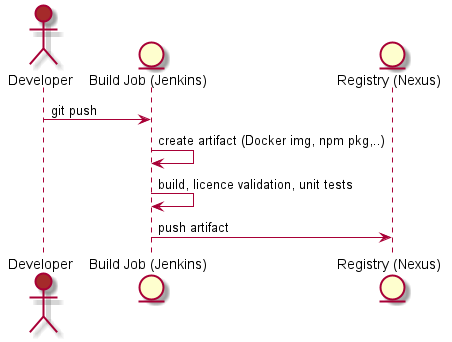
At this moment the continuous integration is done but the features are far from being used by any customer. I have a first feedback that I didn’t brake any tests or other basic constraints but that’s all because nobody can use the features, it is not deployed anywhere yet.
Well let Jenkins execute the next step: deployment to the Kubernetes environment called integration (a.k.a. development)
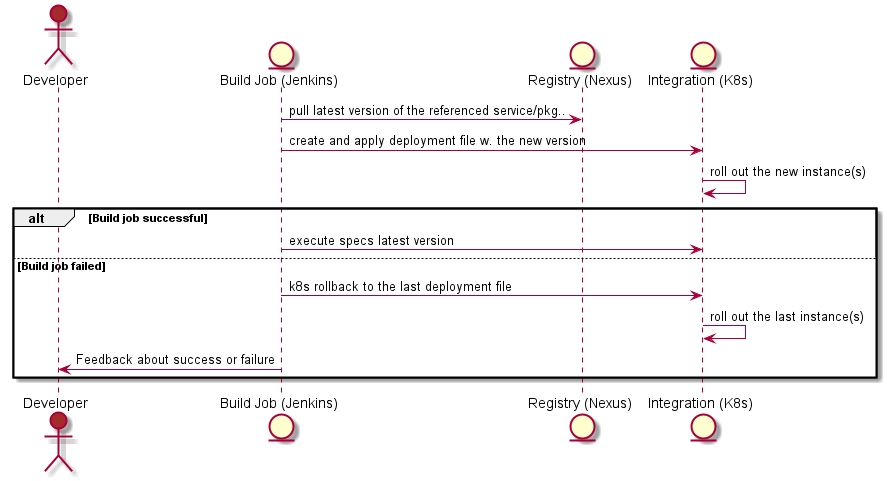
At this moment all my changes are tested if they can work together with the currently integrated features developed by my colleagues and if the new features are evolving in the right direction (or are done and ready for acceptance).
This is not bad, but what if I want to be sure that I didn’t break the “platform”, what if I don’t want to disturb everybody else working on the same product because I made some mistakes – but I still want to be a human ergo be able to make mistakes 😉? This means that my behavioral and structure changes introduced by my commits should be tested before they land on integration.
These must be obviously a different set of tests. They should test if the whole system (composed by a few microservices each having it’s own data persistence, one or more UI-Apps) is working as expected, is resilient, is secure, etc.
At this point came the power of Kubernetes (k8s) and ksonnet as a huge help. Having k8s in place (and having the infrastructure as code) it is almost a no-brainer to set up a new environment to wire up the single systems in isolation and execute the system tests against it. This needs not only the k8s part as code but also the resources deployed and running on it. With ksonnet can be every service, deployment, ingress configuration (manages external access to the services in a cluster), or config map defined and configured as code. ksonnet not only supports to deploy to different environments but offers also the possibility to compare these. There are a lot of tools offering these possibilities, it is not only ksonnet. It is important to choose the fitting tool and is even more important to invest the time and effort to configure everything as code. This is a must-have in order to achieve a real automation and continuous deployment!
I will not include here any ksonnet examples, they have a great documentation. What is important to realize is the opportunity offered with such an approach: if everything is code then every change can be checked in. Everything checked in can be included observed/monitored, can trigger pipelines and/or events, can be reverted, can be commented – and the feature that helped us in our solution – can be tagged.
What happens in a continuous delivery? Some change in VCS triggers pipeline, the fitting version of the source code is loaded (either as source code like ksonett files or as package or docker image), the configured quality gate checks are verified (runtime environment is wired up, the specs with the referenced version are executed) and in case of success the artifact will be tagged as “thumbs up” and promoted to the next environment. We started do this manually to gather enough experience to automate the process.
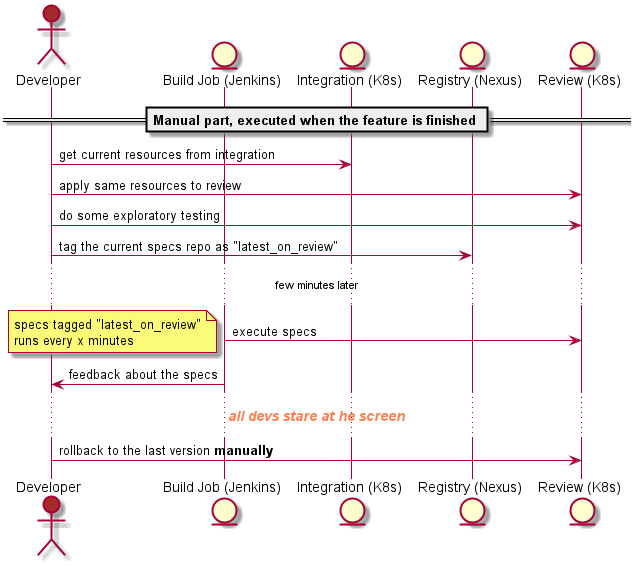
If you have all this working you have finished the part with the biggest effort. Now it is time to automate and generalize the single steps. After the Continuous Integration the only changes will occur in the ksonnet repo (all other source code changes are done before), which is called here deployment repo.
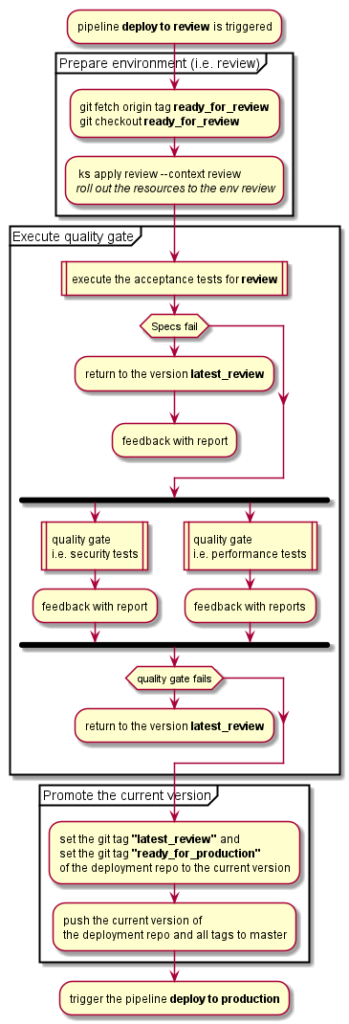
I think, this post is already to long. The next part ( I think, it will be the last one) I would like to write about the last essential method, how to deploy to production, without annoying anybody (no secret here, this is why feature toggles were invented for 😉) and about some open questions or decisions what we encountered on our journey.
Every graphic is realized with plantuml thank you very much!
to be continued …
One thought on “Continuous Delivery Is a Journey – Part 2”
Comments are closed.