In the last months, we started to use these terms more and more at my company without discussing the concepts behind them. One day I was asked, “What do you mean by data ownership?” 🤔 The question made me realise that I don’t know how much of these concepts are understood.
These terms refer to sociotechnical concepts (some originating from Domain-driven design). They refer to one possible answer to the question: how can a product be improved and maintained in the long term? How can we avoid hunting for weeks for bugs, understanding what the code does, finding out what it should do, and hoping that fixing one issue does not lead to a new problem? How can we continue having fun instead of becoming more and more frustrated?
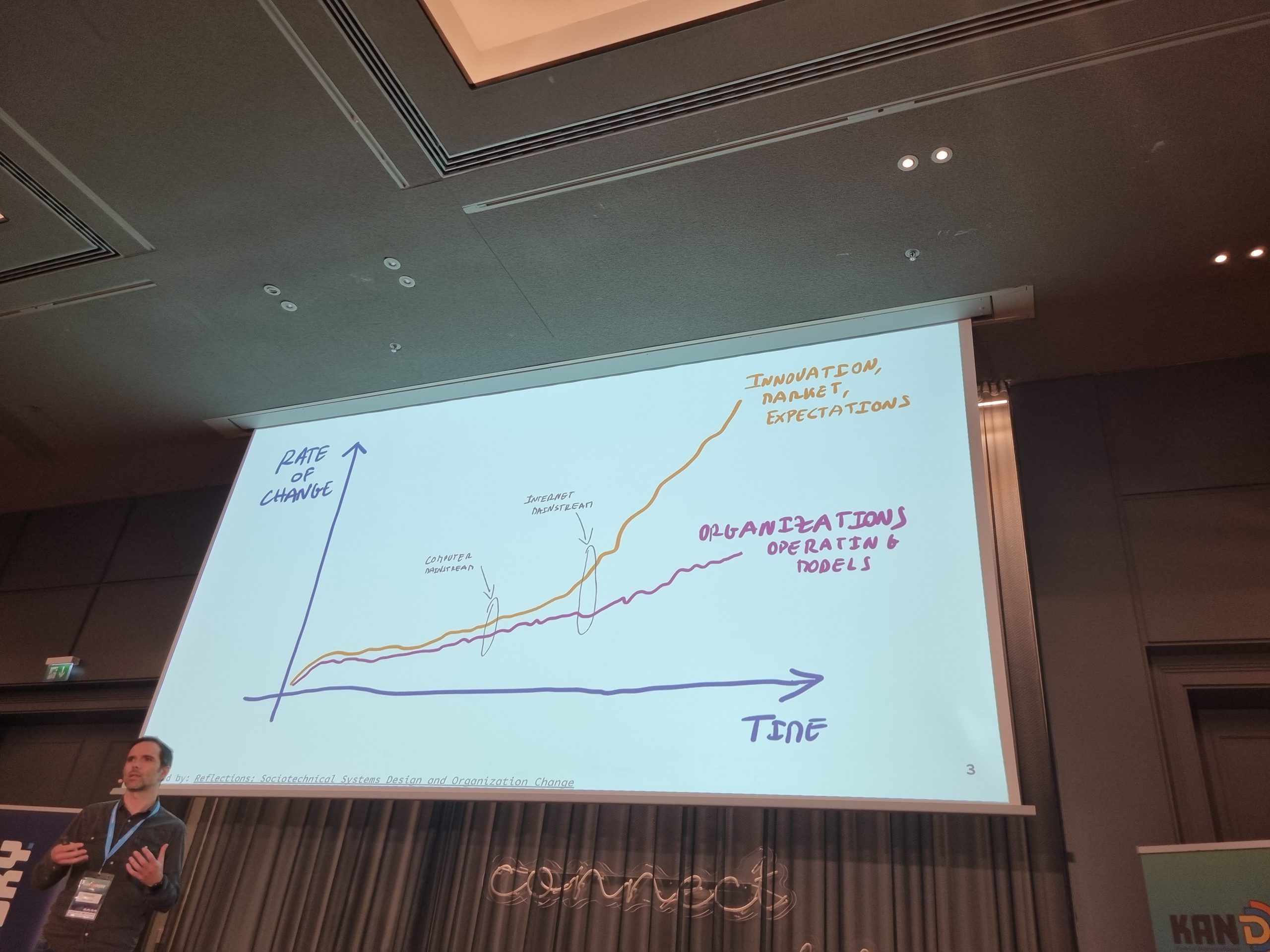
Real digital products address needs which were fulfilled earlier manually. Companies which survived the first years of testing the product are often innovators in their market. They have chances to stay ahead of the others, but they have the burden of solving all questions themselves. I don’t mean the technical questions; nowadays, we have a considerable toolbox we can use. But all the competitors have that toolbox too. The questions to answer are how to organise in teams and how to organise the software to reach a steady pace without creating an over-complicated, over-engineered or over-simplified solution.
How to get a grip on the increasing complexity built up in those years when the only KPI that mattered was TTM (Time-to-Market)?
Years ago, the companies creating software to help automate work answered this question with silos around the architecture: frontend, backend, processing, etc. In the meantime, it became clear that this was not good enough.
Engineers are not hired to type code but to advise and help to solve problems.
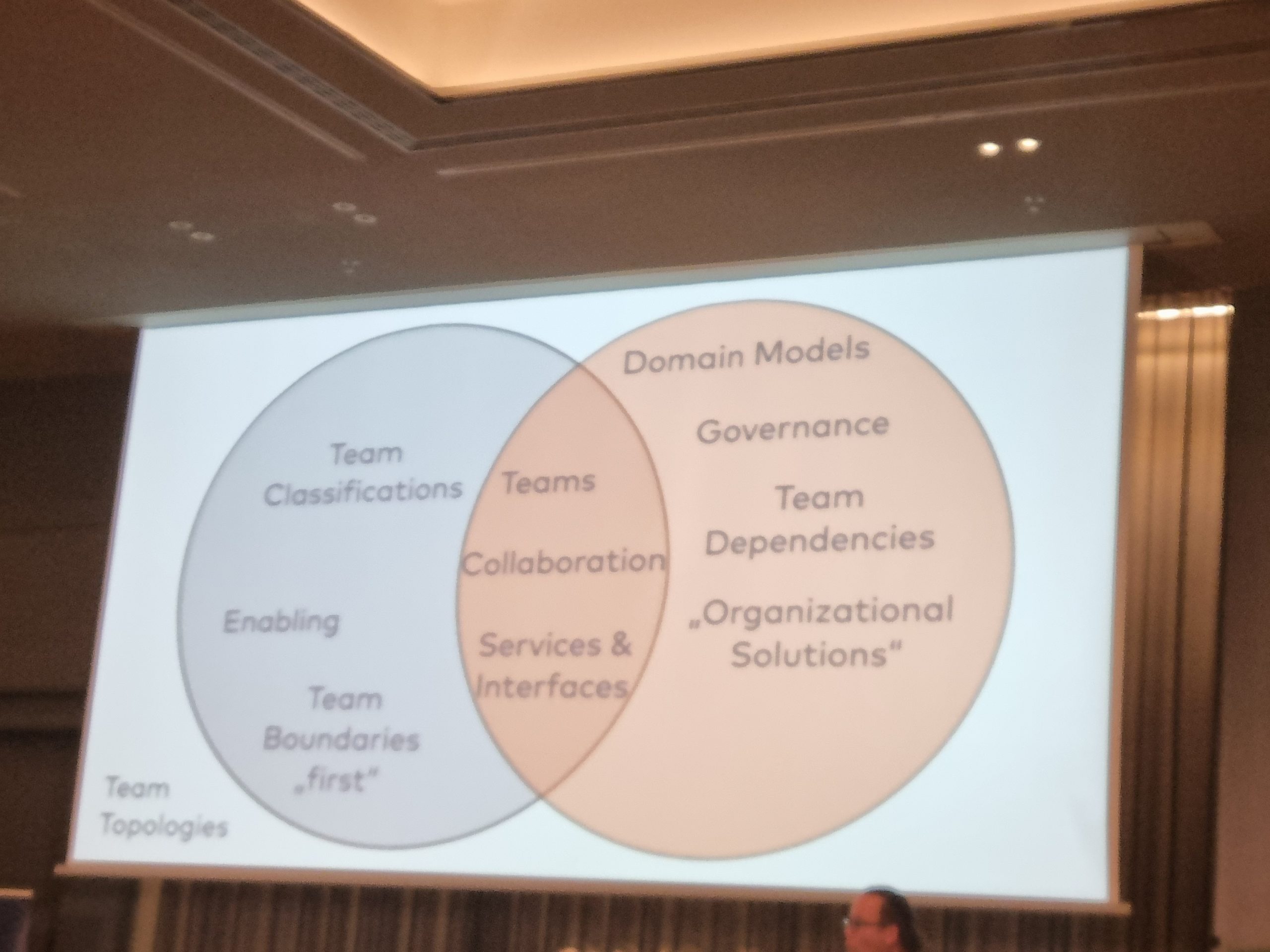
This means they should not belong to an engineering department anymore but be part of teams around different topics to handle: marketing, search, checkout, you name it. These are sub-domains or bounded contexts (depending on the importance of the subject, more than one bounded context can build the solution for the same sub-domain). These contexts and their boundaries are not fixed forever because the context changes, the market around the company changes, and the needs change. The people involved change and, finally, the effort needed changes. The best way also to define them is to take a look at how the business is organised (sales, marketing, finance, platform, developer experience, etc.) and how the companies using the product are organised (client setup, client onboarding, employee onboarding, payroll period, connected services, etc.). By aligning the software and – to get the most significant benefit – the teams to these sub-domains, you can ensure that the cognitive load for each team is smaller than the sum of all.
What are the benefits?
- The domain experts and the engineers speak the same language, the ubiquitous language of their bounded context, to use the DDD terms.
- The teams can become experts in their sub-domain to make innovation and progress easier as the problems are uncovered one after another. They can and will become responsible and accountable about their domain because they are the only ones enabled to do so.
- Each team knows who to contact and with whom to collaborate because the ownership and the boundaries are clear. (No long-running meetings and RFCs anymore by hoping to have reached everyone involved).
What does data ownership mean in this case? Data ownership is not only about which team is the only one controlling how data is created and changed but also the one controlling which data is shared and which remains implementation detail. This way, they stay empowered and autonomous: they can decide about their experiments, reworks, and changes inside their boundaries.
Data ownership also means process ownership.
It means the team which owns the data around “expenses”, for example, owns the features around this topic, what is implemented and when so that they are involved in each improvement or change regarding expenses from the beginning. This is the only way to respect the boundaries, take responsibility, and be accountable for all decisions around the software the engineers create.
Applying these concepts can’t be done overnight, mainly because it is not only about finding the (currently) good boundaries but also shifting the mindset from “let me build something” towards “I feel responsible for this part of my product”. It needs knowledge about the product and a lot of coaching and care. But finding the boundaries to start with should be doable in case of a product already established on the market and with a clear strategy. The alternatives are silos, continuously increasing cognitive load or the loss of an overview and local optimisations.